
Research
From household robots to AI assistants, intelligent systems that operate in the real world must learn continually from the people they serve. My research asks the question: how can robots learn effectively from human partners when feedback is sparse, imperfect, and constantly evolving? To address this challenge, I develop algorithms that enable robots to assess their own uncertainty, recognize when they are misaligned with human goals, and determine when to seek assistance. I study (1) how robots can estimate uncertainty and detect failure in black-box robot policies, (2) how robots can detect misalignment with human intent, and (3) how robots can actively solicit corrective feedback, while (4) designing interaction mechanisms that make intervention and learning more intuitive for human teachers.
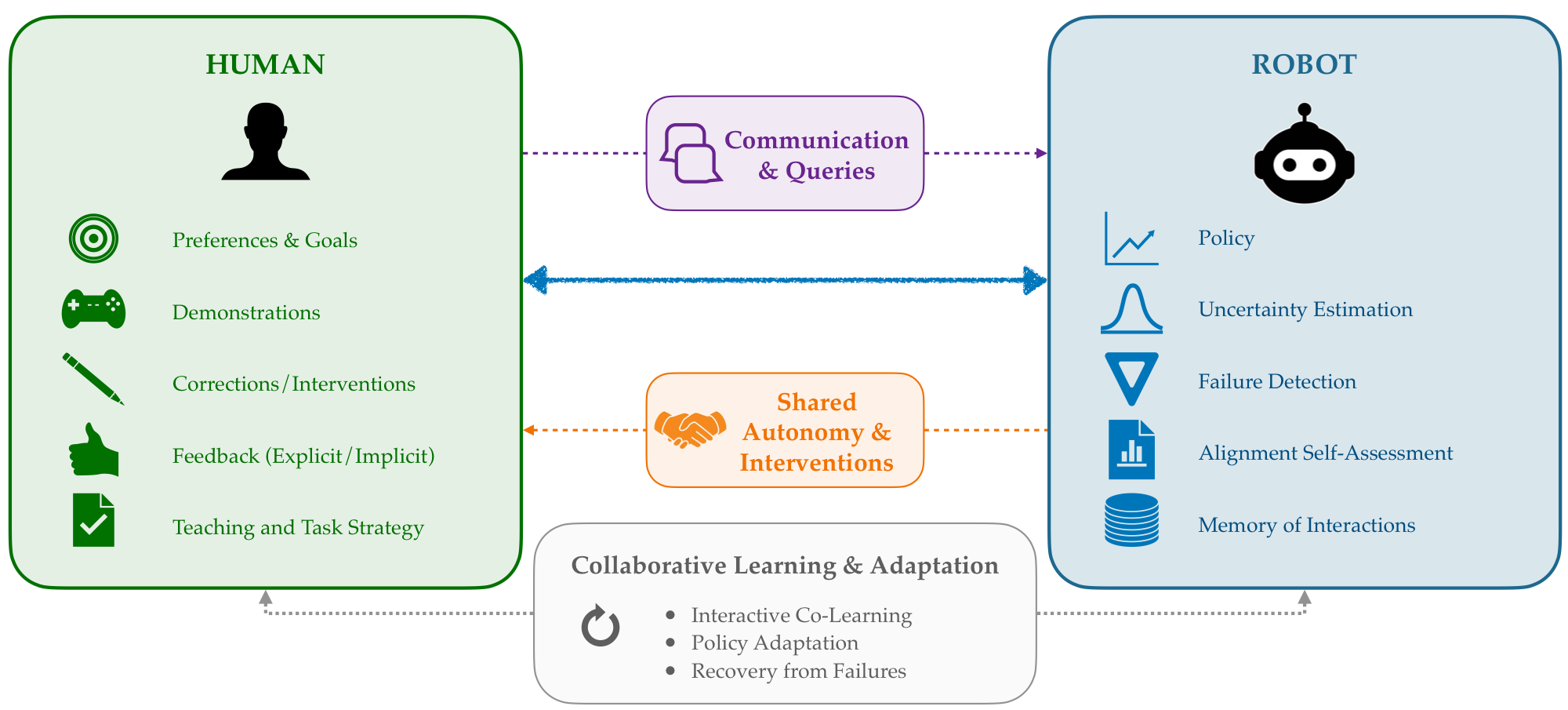
Robots should be able to ongoingly receive human specification, detect when their learned policies fail, reason about when and why human input is needed, incorporate demonstrations and corrections into future behavior, and adapt to evolving human preferences over time.
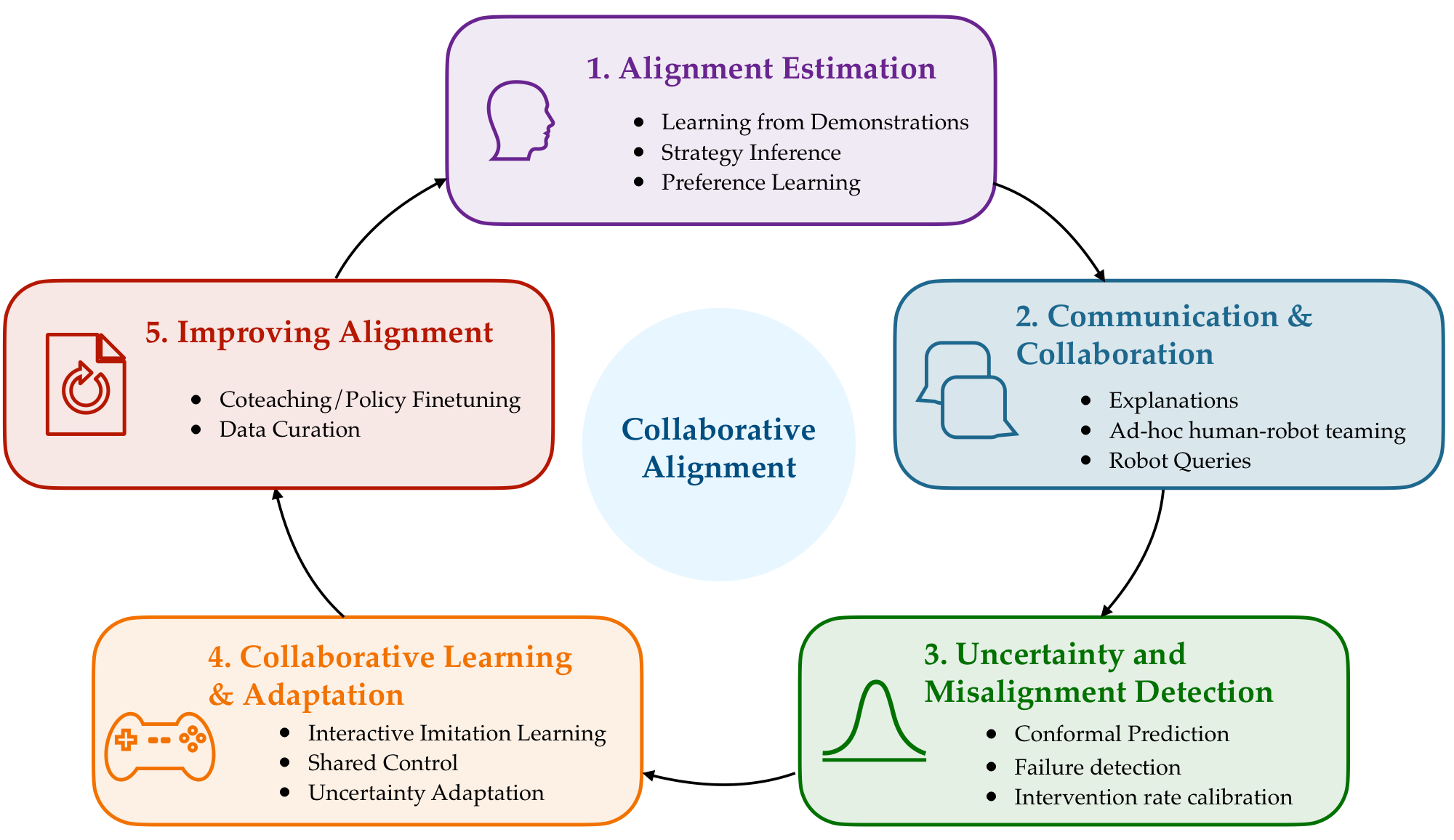
Interactive Learning from Human Feedback
Robots deployed in the real world face distribution shift, novel tasks, and shifting user preferences. The most reliable source of correction is the human in the loop. And we can use human correction to help robots detect when their action predictions are misaligned with human intent. My work develops algorithms that let robots learn continually from rich human feedback: demonstrations, corrections, and preferences.
A central challenge is that the human teacher is not a static oracle. Their attention is intermittent, their feedback can be noisy or contradictory, and their goals can change mid-deployment. And even after training a policy, the robot policy might still fail! I design learning procedures that are robust to these realities, and allocate human input to where it is most effectively spent.
Relevant work: Optimal Interactive Learning on the Job via Facility Location Planning (RSS 2025); Conformalized Interactive Imitation Learning (ICLR 2025); LLMs for Preference-Based Sequence Prediction (ICAART 2025).
Uncertainty Quantification for Robot Policies
How does a black-box robot policy know when it doesn't know? I use conformal prediction techniques to give robot policies calibrated confidence over their own decisions across both teleoperated assistance and imitation-learned policies.
This lets robots flag risky states before acting on them, defer to a human when out of their depth, and ask for help in a way that preserves task progress rather than interrupts it. The aim is to move beyond best-effort autonomy toward robots that are honest about the limits of what they have learned.
Relevant work: Conformalized Teleoperation (RSS 2025); Conformalized Interactive Imitation Learning (ICLR 2025).
Communicating Robot Capabilities with Humans
How does a human know how to use a robot when they don't know what it is capable of? Robots capable of multiple skills or strategies need to communicate their capabilities to human teammates, so the human align complementary contributions and know when to step in. And when robots are uncertain, they need to explain what they're uncertain about and why, so the human can provide feedback that actually helps.
This work develops methods for robots to explain their high-level strategies and behavioral preferences to human teammates, making collaboration more legible and predictable. Afterwards, humans can inform the robot how they want the robot to behave, and the robot can adapt to meet those expectations.
Relevant work: Multi-Agent Strategy Explanations for Human-Robot Collaboration (ICRA 2024).
Active Learning on the Job
When a robot is already deployed, every query to a human teammate has a cost: it interrupts the task, fragments the user's attention, and consumes time.
I design algorithms that decide when and what to ask in deployment, framing query selection as a planning problem that balances progress across a multitask sequence, the marginal value of new information, and the teacher's limited bandwidth. The result is robots that improve over the course of a deployment without wearing out the people they're trying to help.
Relevant work: Optimal Interactive Learning on the Job via Facility Location Planning (RSS 2025).
Coordination & Adaptation in Human-Robot Teams
Effective teammates model each other and adapt. Collaborative robots need to infer their partner's strategy, communicate their own intentions, and adjust their behavior to support fluent joint action.
My work in this thread spans collaborative manipulation, shared autonomy, and assistive robotics, and asks how strategy matching, intent explanation, and contribution-preference modeling can be operationalized in real collaborative tasks. The throughline is that robots that model the collaboration as a user-desired objective over robot and human actions can better align with human goals and adapt to evolving preferences over time.
Relevant work: Multi-Agent Strategy Explanations for HRC (ICRA 2024); Learning Human Contribution Preferences (CoRL 2023); Coordination with Humans via Strategy Matching (IROS 2022); The Role of Adaptation in Human-AI Teaming (topiCS); Teaching Agents to Understand Teamwork (Computers in Human Behavior, 2022).
Robot Learning from Heterogeneous and Novice Users
Teaching a robot isn't easy! People naturally differ in the ways they perform a task, but also how capable they are of teleoperating a robot, providing demonstrations, or giving feedback. Robots that learn from people need to be robust to this heterogeneity, and adapt to the needs of novice users.
Aggregating corrective data from multiple teachers can lead to worse performance than learning from a single teacher, and that the key to success is to separate what data is beneficial from what is not, and detecting when new input is misaligned with what a robot policy has already seen.
Relevant work: Conformalized Teleoperation: Confidently Mapping Human Inputs to High-Dimensional Robot Actions (RSS 2025).